LLM architecture refers to the structural design of a large language model — the arrangement of neural network layers, attention mechanisms, and training objectives that determine how the model understands and generates text.
All major LLMs today, including GPT-4, Llama 3, and Gemini, are built on the transformer architecture, introduced by Google researchers in 2017.
Large language models are now core infrastructure. From enterprise chatbots to AI-assisted code generation, organisations are embedding LLMs into critical workflows. Yet for many IT professionals, how these models actually work remains opaque — a black box evaluated by output quality rather than engineering merit.
That is a strategic liability. Teams that understand LLM architecture make better vendor decisions, deploy more reliably, and govern AI systems with greater confidence. This guide provides the technical foundation to do exactly that.
How does the transformer model work?
The transformer is the foundational architecture behind every major LLM. Introduced in Vaswani et al.'s 2017 paper "Attention Is All You Need", it replaced recurrent neural networks by processing all tokens in a sequence simultaneously — enabling parallelised training at massive scale.
Self-attention: the core mechanism
Self-attention allows every token in a sequence to dynamically weight its relationship to every other token. Multi-head attention runs this process in parallel across multiple learned representations, capturing syntax, semantics, and context simultaneously — a fundamental departure from earlier NLP architectures.
IT implication: The attention mechanism is computationally quadratic with sequence length. Longer context windows require significantly more GPU memory — a key factor in infrastructure planning.
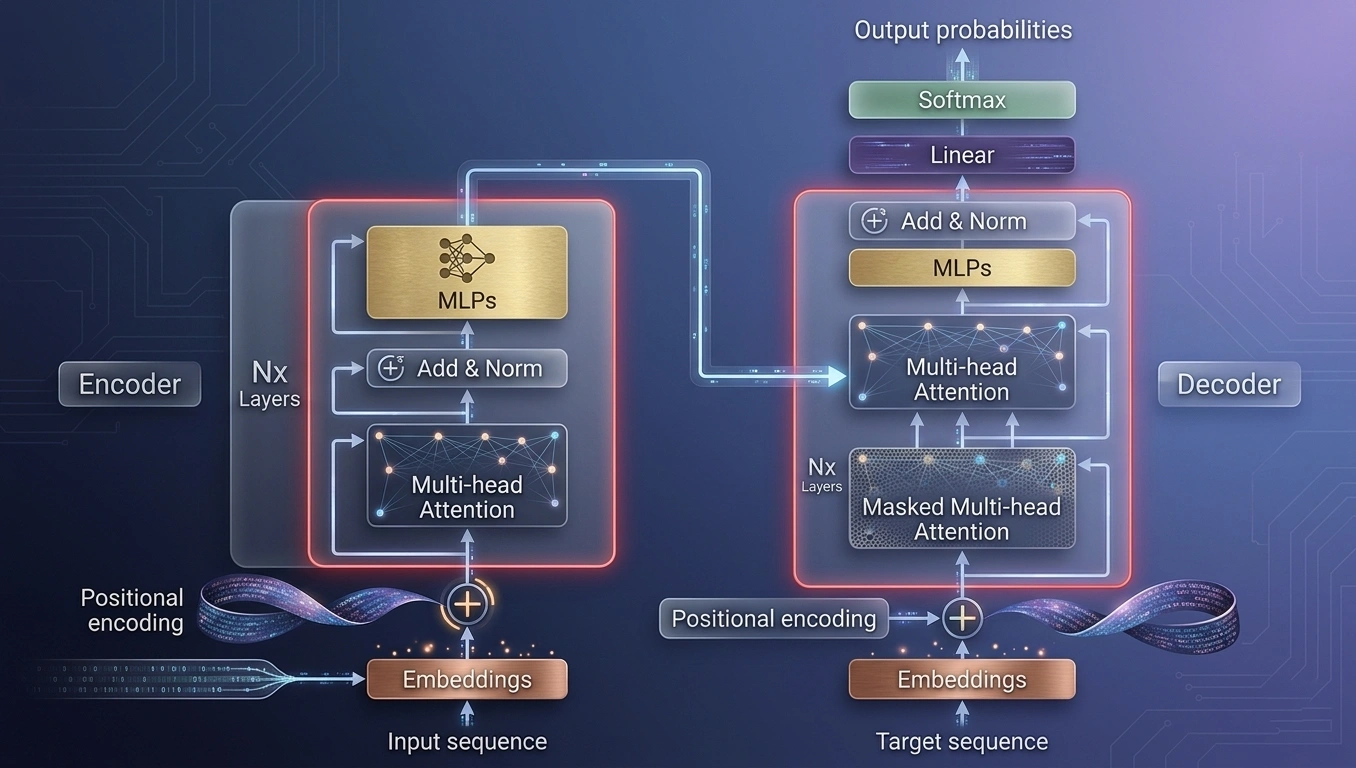
Figure 1: The Transformer architecture — encoder and decoder blocks with multi-head attention mechanisms
What are the core components of LLM architecture?
Tokenisation and Embeddings
Text is converted into subword tokens, then mapped to high-dimensional vector representations via embedding layers. The tokeniser's vocabulary size and design directly affect performance on domain-specific content — critical when fine-tuning models for enterprise use cases.
Positional Encoding
Because transformers process tokens in parallel, they require positional encodings to understand sequence order. Modern variants — RoPE (Rotary Position Embedding) and ALiBi — improve generalisation to longer sequences, directly extending the usable context window.
Key Variants: RoPE, ALiBi — both designed to extend context windows beyond traditional limits
Feed-Forward Networks & Layer Normalisation
Each transformer block contains a feed-forward network (FFN) introducing non-linearity and expanding model capacity. Layer normalisation applied before or after each sub-layer stabilises training at billion-parameter scales — a prerequisite for reliable convergence.
Non-linearity
Stabilisation
Context Windows Comparison
The context window defines the maximum token input the model processes in a single pass. For IT architects, it directly governs use-case viability.
How does model size affect LLM performance?
Model size — measured in parameters — correlates with capability up to a point. DeepMind's 2022 Chinchilla paper showed that optimal performance requires scaling training data proportionally alongside parameters.
More parameters without more data yields diminishing returns.
| Model | Parameters | Organisation | Year | Type |
|---|---|---|---|---|
| GPT-3 | 175B | OpenAI | 2020 | Proprietary |
| PaLM | 540B | 2022 | Proprietary | |
| GPT-4 | ~1T+ | OpenAI | 2023 | Proprietary |
| Llama 3 | 8B / 70B / 405B | Meta | 2024 | Open weights |
| Mistral 7B | 7B | Mistral AI | 2023 | Open weights |
Training compute-optimal language models requires scaling both parameters and data tokens proportionally.
— Hoffmann et al., DeepMind (2022)
IT decision point: Smaller open-weight models like Llama 3 8B increasingly match larger proprietary models on targeted tasks. Model selection should balance capability, latency, data sovereignty, and total cost of ownership — not parameter count alone.
How are large language models trained?
Parameter-Efficient Fine-Tuning Techniques
Low-Rank Adaptation updates only low-rank adapter matrices, reducing trainable parameters by up to 10,000x with minimal accuracy loss.
Combines LoRA with 4-bit quantisation, enabling 65B-parameter fine-tuning on a single 48GB GPU.
Trains lightweight soft prompts prepended to inputs — lighter still for narrow, specific tasks.
How do you deploy LLMs in production?
Inference Backends
Production LLM serving requires GPU-accelerated hardware and optimised inference frameworks.
- vLLM
- TensorRT-LLM
- Hugging Face TGI
Continuous batching, flash attention, KV cache management
Quantisation
Quantisation compresses model weights from FP32 to INT8 or INT4 formats, shrinking memory requirements.
GGUF format enables consumer-grade hardware deployment
RAG
RAG pairs an LLM with an external vector database. At inference time, semantically relevant documents are retrieved.
Compliance Advantage
Keeps sensitive enterprise data out of model weights entirely — preferred for regulated industries.
What are agentic LLM architectures?
Agentic LLM architectures enable models to autonomously plan, reason across multiple steps, and use external tools — such as APIs, code interpreters, and search engines — to complete complex tasks.
This moves LLMs from reactive responders to active workflow participants.
The ReAct Pattern
The ReAct (Reasoning + Acting) pattern interleaves chain-of-thought reasoning with tool invocations, allowing iterative task decomposition.
Graph-based agent orchestration with tool use and persistent memory.
Multi-agent conversation framework enabling agent-to-agent task delegation.
Role-based multi-agent teams for structured enterprise workflow automation.
For IT architects, agentic systems introduce new challenges: non-deterministic behaviour, prompt injection risk, and the need for robust observability tooling. These are engineering problems, not just AI problems.
Frequently asked questions about LLM architecture
What is the difference between an LLM and a transformer?
A transformer is the neural network architecture; an LLM is a large-scale application of that architecture trained on vast text data. All major LLMs use transformer architecture, but not all transformers are LLMs.
How many parameters does a typical LLM have?
Production LLMs range from 7 billion parameters (Mistral 7B) to over one trillion (estimated GPT-4). Enterprise use cases increasingly favour models in the 7B–70B range.
What is a context window in an LLM?
The context window is the maximum number of tokens the model can process in a single request. Larger windows enable longer documents and multi-turn conversations but increase compute cost proportionally.
What is RAG and why does it matter?
Retrieval-Augmented Generation (RAG) supplements an LLM with real-time retrieval from an external knowledge base. It reduces hallucinations and keeps models current without retraining.
What is the difference between fine-tuning and RAG?
Fine-tuning updates model weights with domain-specific data, embedding knowledge permanently. RAG retrieves information at inference time without changing weights.
Are open-weight models like Llama 3 suitable for enterprise use?
Yes, increasingly so. Llama 3 and Mistral variants match or exceed proprietary models on many enterprise benchmarks at a fraction of the cost, and offer data sovereignty advantages.

